
Bonetflix February 2024 marketing updates
Bonetflix marketing results and X bot problems

In a recent edition, I delved into the world of Bonetflix, exploring its data and strategies for boosting its online presence. Following that, I shared insights on prime locations for startup promotion in the "Discover Top Spots for Your Startup" issue. I positioned Bonetflix in these spots, aiming to enhance its SEO performance. Subsequently, I employed the Google Index API to index pages overlooked by Google, a subject covered in "Updates on My Recent Ventures and Discoveries." Now, let's delve into the developments stemming from those endeavors.
The current state of the Bonetflix search console is illustrated in the image below:
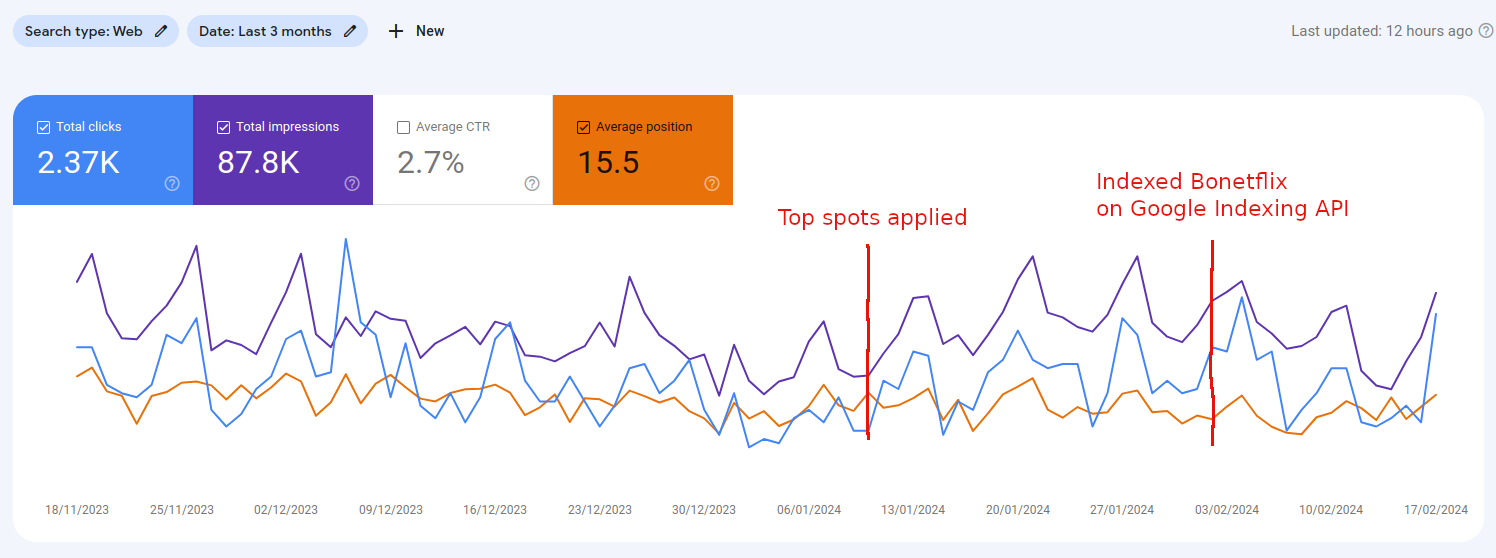
This image highlights the creation of numerous backlinks through strategic placements, contributing to a modest improvement in Bonetflix's rankings. While not a revolutionary change, it signifies progress.

In the realm of indexing, Google Search API doesn’t index web pages when dealing with problematic web pages. Here is a summary of my indexed pages and identified issues:


I will work on fixing those issues before trying again Google indexing API.
Bot problems on X
A previous installment, “Updates on My Recent Ventures and Discoveries” chronicled my progress on X. But it turns out part of Bonetflix followers are not real. Around February 14th, X took action against bot/followers associated with Bonetflix and Bonetflix US, unveiling the prevalence of fake engagement. My engagement was fake and the problem is that other bots keep following Bonetflix accounts. Regrettably, other bots persist in following Bonetflix accounts, displaying common characteristics:
Accounts were created in 2023.
Followings ranging from 2000 to 5000.
Limited followers.
Profile picture featuring an attractive woman.
Typically devoid of posts or featuring posts with links to external websites.
Addressing this persistent issue is crucial, and while there are market solutions, none are foolproof, as there could always be ways to bypass them.
If X gathers the following data, it could perform actions to protect better against bots:
Fingerprint user agent and environment.
Track user actions within X.
Check user IP’s reputations and locations.
Utilizing this data, a model could be trained to detect the likelihood of a user being a bot. If the probability is moderate, implementing randomized challenges at various points and steps could deter bots. These challenges can be influenced by time, complexity and required resources. Ideally, challenges should remain dynamic and not repeat. In instances of high bot probability, blacklist the user and prompt contact via email. If bots attempt to circumvent challenges, leverage these challenges for X's benefit, using them for data labeling purposes, similar to Google's approach.
Next Strategy to Explore
Recently, I came across the concept of Parasite SEO. This strategy involves leveraging the authority and traffic of established websites to enhance the ranking of another site. I will relate this journey in future issues.